
Automating Generative AI Evaluation: A Path to Consistency and Speed
- Jie Nissel, Samarth Somani, Laura Setzer, & Chloe Pinkston
- 5 min read
Ally’s “do it right” mantra guides our technology roadmap – including our Generative AI strategy, which keeps humans at the center of decision-making. Large language models (LLMs) such as those offered by OpenAI, Gemini, and Anthropic have enhanced the efficiency and scope of text analysis, vision and reasoning tasks, but their value hinges on the ability to evaluate them quickly, consistently, and at scale. In a world where “speed to insight” equals competitive advantage, manual reviews and ad-hoc benchmarks have a difficult challenge in keeping pace. We are exploring how automating the Generative AI evaluation process could help streamline the experimental cycle and potentially accelerate our understanding of Generative AI in enhancing consistency, scalability, and speed in evaluations.
The Challenge of Generative AI Assessment
Evaluating LLM outputs presents unique challenges. The inherent nondeterminism of LLMs means they may produce a distribution of responses to identical prompts, which poses a challenge in maintaining consistency across outputs. Additionally, subjective quality judgments complicate the evaluation process, as determining what constitutes "good" output can vary—accuracy, relevance, fluency—and stakeholders can often disagree on these criteria. Fragmented benchmarks further exacerbate the issue, with different teams running various tests, leading to apples-to-oranges comparisons. Manual bottlenecks also slow down the process, as human review becomes more complex as the scale increase.
Building Blocks of an Automated Framework
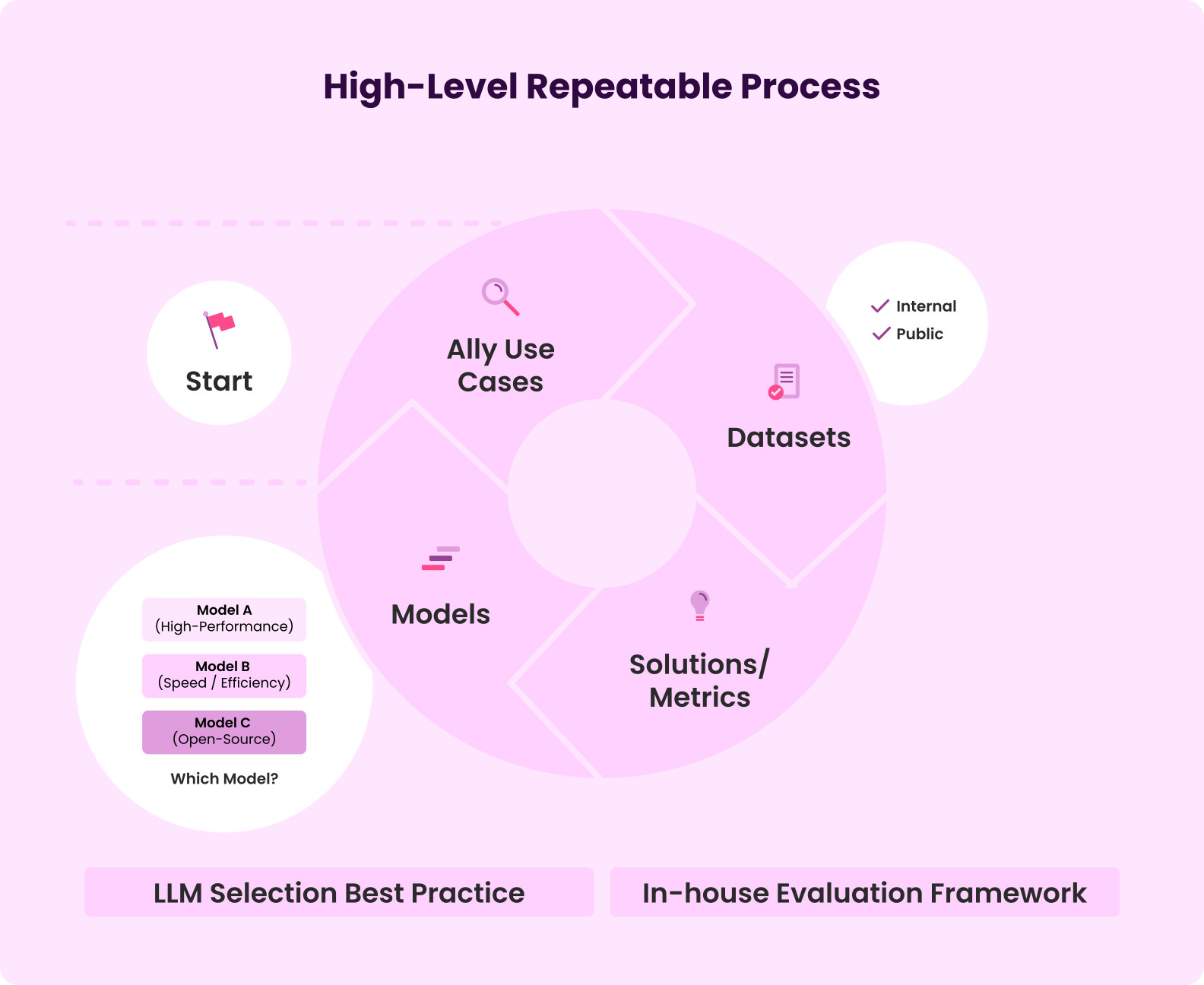
To address these challenges, an end-to-end workflow was designed to enhance the evaluation process for Generative AI technologies. The first component involves the curation of benchmarks. This entails assembling representative, high-quality datasets that are comprehensive and reflective of real-world applications. Maintaining versioned “gold” standards ensures that every model is judged against the same ground truth, providing consistency in evaluations. Regularly refreshing benchmarks to adapt to new product requirements, domains, or compliance rules keeps the evaluation process relevant and up to date.
The second component is a modular evaluation toolkit for the Generative AI workloads, such as Summarization, Document Question & Answer, and Code Generation. It provides workload-specific metrics and scripts that make testing faster, easier, and more consistent.. While each metric is implemented as a reusable function to facilitate smoother integration of new models or datasets, all implementations must still pass through rigorous human validation and comply with existing governance frameworks.
The third component is the Standardized Metrics Suite. Task-specific metrics are provided, managed internally, and tested with internal data. Each metric is implemented as a reusable function, allowing new models or datasets to plug in seamlessly. By codifying these components, one-time evaluation scripts are eliminated, and a self-service portal is created for team members to use.
Lessons Learned
Several lessons were learned during the development of this automated framework. Starting small and iterating fast proved crucial. The first dashboard prototype had to be scrapped entirely due to its speed, highlighting the importance of rapid iteration and continuous improvement.
Measuring what matters is another key lesson. Our team spent two weeks optimizing a model to score higher on “ROUGE” metrics but discovered that internal users to our platform cared more about whether the model’s outputs were logically consistent (entailment) rather than lexically similar to reference texts. This learning helped us avoid a common pitfall in model evaluation: optimizing for metrics that seem relevant but do not result in the purpose of the model or the needs of the user.
Inviting stakeholders early in the process uncovered valuable insights. Product managers provided feedback that led to UX tweaks that would not have been considered otherwise. Early stakeholder involvement can significantly improve the final product.
Next Steps: Embedding into CI/CD and Governance
The journey toward optimizing Generative AI evaluation is filled with exciting possibilities for us, where our evaluations can be potentially seamlessly integrated into CI/CD pipelines, automatically triggering assessments on new model checkpoints and providing immediate feedback. Such advancements could ensure continuous monitoring and rapid identification of issues, paving the way for more robust and reliable models.
Governance workflows could evolve to incorporate metric thresholds into Model Risk Management requirements, embedding evaluation processes into compliance checks. This would enhance reliability and ensure that models meet stringent standards before deployment.
Expanding the scope of the automated evaluation framework to include new modalities, such as vision tasks (image-to-text), opens a realm of comprehensive assessments. These innovations could lead to more versatile and powerful Generative AI applications, addressing a broader range of challenges and opportunities.
Conclusion
Automating Generative AI evaluation is not just about speed; it is about consistency, repeatability, and accuracy. Performing human evaluation for each model update leaves significant value on the table. By adopting an automated within the broader AI governance evaluation framework, including humans remaining in the loop within the broader AI governance framework, reliable and scalable assessments are ensured, accelerating the Generative AI pipeline and enhancing overall efficiency.
Interested in joining Ally's team of talented technologists to make a difference for our customers and communities? Check outAlly Careersto learn more.