
Chaos Testing: Improving System Resilience
- Divyeshkumar Patel
- 5 min read
Over 10 million customers are trusting Ally’s digital platforms to be available when they need it. With the increasing complexity of real-time systems, distributed across computing ecosystems, resiliency has become even more critical than ever. To meet the pre-defined application Recovery Time Objective (RTO) and Recovery Point Objective (RPO) requirements, Ally is implementing the chaos testing framework. We are continuously expanding the new testing patterns that is a game-changer for Product quality which is designed to simplify the testing process and improve overall quality. Chaos Engineering has become a popular methodology for businesses to test the resilience and reliability of their systems. In this blog post, we will discuss how chaos testing works, its principles, advantages, and the Ally developed framework that we have implemented using Cloud & DevSecOps platforms to make sure our systems are resilient to handle any failure event.
How Chaos Testing Works?
Chaos testing is different from traditional testing. Instead of verifying that the system works as expected, chaos testing focuses on finding potential failure in distributed computing systems before they cause problems. This technique involves injecting controlled failures into the system to observe how it behaves and identify potential weaknesses. The implementation of experiments and hypotheses is followed by comparing the results with the steady state. Based on AWS research, FIS can help reduce 20% of unplanned events. According to a Gartner report, by 2025, 40% of organizations will implement chaos testing and improve mean time to repair (MMTR) by an average of 90%.
Advantages of Chaos Testing
While we’re early in our journey, we’ve already observed several benefits from chaos testing which are listed below
Improving system performance and resilience
Exposing blind spots using monitoring, observability, and alerts
Proactively validating the resiliency of the system in the event of failure
Learn how systems handle different failures
Preparing and educating the engineering team for actual failures
Increasing end-user and stakeholder satisfaction
Improve architecture design to handle failures
Principles of Chaos Testing
Chaos testing is designed to create thoughtful plans and experiments to proactively mitigate risks within large distributed systems and networks. The following principles were followed during chaos testing:
Plan: Develop a plan for conducting chaos testing experiments that identify the system’s potential weaknesses. Decide what you want to test and how you’re going to do it.
Experiment: Perform the planned chaos testing experiments and gather data on the system’s behavior during each test.
Analysis: Analyze the data collected during the experiments to identify potential weaknesses in the system.
Mitigate: If you find an issue, you can end your experiment, take steps to mitigate the identified weaknesses in the system and improve its resilience.
Prerequisite for Chaos Testing
Before performing the chaos testing there are several prerequisites that need to be met for successful testing.
Basic Monitoring — The system should have monitoring and observability tools in place to collect and analyze data on system behavior.
Organizational Awareness — The stakeholders for the systems should be informed and onboarded with the chaos testing methods, goals, and risk.
Real world events — Select the fault injection scenario that is close to the actual incident that team had observed earlier.
Remediate — Chaos testing end goal is to make the system resilient. If any issue is identified during the chaos testing, then work to mitigate and fix the issue.
Workflow
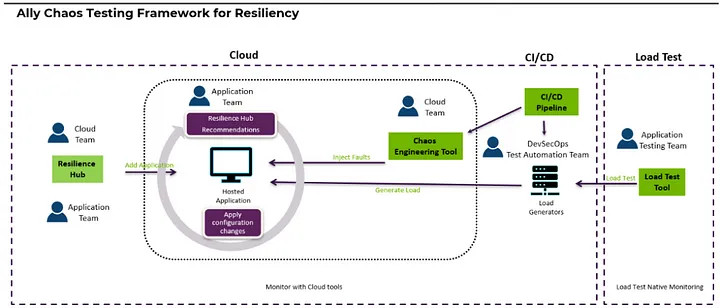
At Ally, we have developed our chaos testing framework using Cloud Resilience Hub, Chaos Engineering tool, and Load Test tool. The main idea behind our framework is to combine performance testing and chaos engineering. When we replicate a system failure, it is important to have real users on the system to observe the impact of the failure on the user experience. The following steps were taken during the workflow:
Add Application on the Cloud Resilience Hub: Analyze the components of the application and uncover potential resilience weaknesses. Resilience Hub will assess & uses best practices from the well-architected framework to analyze the components of an application, uncover potential resilience weaknesses and then provide an actionable recommendation to improve resilience. This is our framework prerequisite; all applications must be added first on Resilience Hub and then apply the recommendation.
Create a Fault Injection Experiment in Chaos Engineering Tool: Develop a fault injection experiment based on the services that the application uses. On the Chaos Engineering Tool, you can create multiple fault injection actions. Before you create an experiment, you need to know the IDs of all the services that the application uses. Based on the application service usage you can create an action and select the target resource.
Develop an Application Load Test Script: Use the Load Test tool to develop a performance testing script and create real-world traffic on the systems. Before the actual test, run a smoke test and get an application base line response result.
Execute Load Test & Inject Fault Experiment Scenario: Chaos testing is in action. Once first 3 steps are completed, schedule a Game Day session. It is important to include all stakeholders as they play a key role in identifying and resolving the issues in case a failure is identified.
Observe an application behavior and analyze the results: Monitor the application behavior. While the Load Test & Fault injection experiment is being performed, monitor the application behavior with Cloud Platform and Load Test native monitoring dashboard.
Mitigate an issue: Prioritize and plan to fix any issues identified during the testing. Any observed issue should be the priority and a plan to fix it should be created. Once the issue is fixed, the chaos testing is restarted following step 1 of the workflow. This is continuing process to keep the systems resilient.
Conclusion
Chaos testing is a crucial methodology for testing the resilience and reliability of complex distributed systems. It is not a one-time activity; it has to be a continual process to achieve the desired outcome. Ally is implementing chaos testing to minimize unexpected downtime, enhance user experience, and promote the adoption of this approach to reduce the mean time to repair. By conducting chaos testing, we aim to proactively identify and address potential system failure and bottlenecks before they impact our customers. We believe that this proactive approach will help us maintain the highest standards of service and quality, while also setting an example for other organizations to follow. We encourage everyone to explore the benefits of chaos testing and embrace it as a best practice for ensuring resilient and reliable systems.
Interested in joining Ally's team of talented technologists to make a difference for our customers and communities? Check outAlly Careersto learn more.